


 4008-622-911
4008-622-911




ROCKCHIP瑞芯微RK3588S样板原理图分析
今天看瑞芯微RK3588S样板原理图,看到了之前分析过的两个电路,所以截取出来与各位同好一起学习一下器件选型取值。
电路1
首先是这个控制电源的电路,感觉用的频次还是很高的,还是蛮实用的。
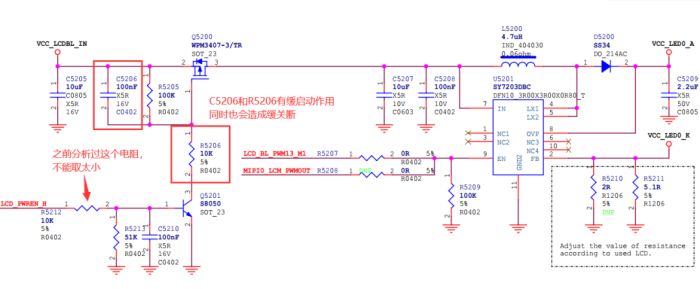
需要注意的是C5206和R5206是起缓启动作用的,但是由于C5206的本质是增加了PMOS的Cgs电容,所以在启动缓启动的同时,也会关断缓关断。(Cgs充放电时间都变长)可以电路需求更改电容和电阻从而更改缓启动时间。
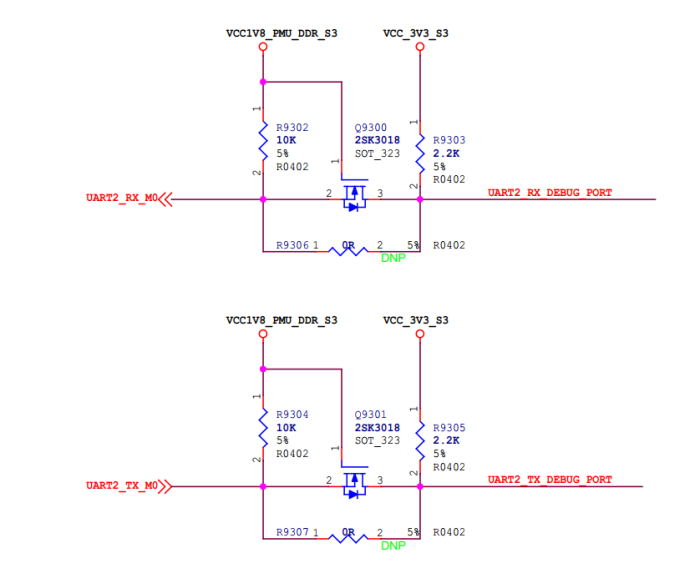
电路2
然后在原理图中也看到了这个电平转化电路,感觉器件取值各位可以借鉴一下。


相关推荐
-

-
村田murata电容命名规则murata电容编码规则
murata村田电容公司的型号命名规则是基于产品的特定属性和性能特征。型号通常由字母和数字组成,字母代表电容的用途和特殊功能,数字表示电容的额定容量和电压等级。例如,型号GRM188R71H104KA93D表示该电容为SMD多层陶瓷电容,额定容量为100nF,电压等级为50VDC。murata村田制作所是一家电子元器件制造商,其主要产品包括贴片电容、电感和滤波器等。客户遍布于个人电脑、手机、汽车电子等领域。深圳永芯易科技将为您详细讲解村田murata电容的型号命名规则及方法。举个例子,我们来分析一下GRM32ER61A107ME20L(1210X5R10V100UF20%)这个murata贴片电容的构成。一、GR是指村田murata贴片电容系列中的型号之一,该系列还包括GC、GJ、GM、GQ、KR、LL等型号。二、M系列代表村田murata贴片电容器,包括型号H、M、A、D、3、J、L。三、32代表电容器的尺寸:村田贴片电容器的尺寸范围从0201到0402到0603到1206到1210到1812到2220(32指的是长宽为3.2毫米*2.5毫米的尺寸,即我们熟知的1210电容器)。四、E代表村田贴片电容的厚度为2.5毫米。常用的厚度有5=0.5毫米、6=0.6毫米、8=0.8毫米、9=0.9毫米、B=1.25毫米、C=1.6毫米和E=2.5毫米。五、R6代表村田贴片电容采用的X5R材料。除此之外,常见的村田电容代码还包括5C、R7和F5等,它们所代表的材料分别为COG/NPO/CHR6、X7R以及Y5V。对应的具体数值如下:5C为COG/NPO/CHR材料、R6对应X5R材料、R7为X7R材料、F5为Y5V材料。5C的工作温度范围为零下55度至正125度,其温度系数为0到负正30ppm/度。R6的工作温度范围为-55度至+85度,具有温度系数为正负15%。R7的工作温度范围为零下55摄氏度至正125摄氏度,温度系数在正负15%之间。F5的工作温度范围为-30度至85度。该产品的温度系数为+22和-82%。六、1A代表的电压是10V,而村田贴片电容通常使用的电压等级有0J、1A、1C、1E、1H等,它们对应的电压值如下:0J=6.3V,1A=10V,1C=16V,1E=25V,1H=50V。七、107代表电容器的容量为100微法。八、M代表的是精度+-20%,常用的档位有B、C、D、J、K、M、Z,具体对应的值如下:B=+-0.1pF,C=+-0.25pF,D=+-0.5pF,J=+-5%,K=+-10%,M=+-20%,Z=+80,-20%。九、E20是村田murata公司的内部代码,对外无关紧要。10、L代表包装方式:直径为180毫米的压纹带(塑料)编带盘装,D代表直径为180毫米的纸带编带盘装;B代表散袋装。以上就是关于村田murata电容命名规则murata电容编码的解释
-

-
MPS美国芯源汽车 SoC 核心轨供电的挑战与机遇
简介汽车行业正经历重大的变革,电动汽车 (EV)、自动驾驶、高端信息娱乐系统、连接性,还有软件定义汽车。无论是电动汽车的目的、益处,还是它对汽车供应链的影响,人们都已经有了深刻的认识。然而,向自动驾驶和高性能计算 (HPC) 的数字化转型仍处于早期阶段,它还在不断的发展中。数字化转型同时适用于电动汽车和内燃机 (ICE) 汽车。这些新兴趋势带来的技术颠覆将为汽车供应链带来挑战,同时也带来机遇。人口的持续增长和城市化,让现代交通面临拥堵、事故多和交通不畅等问题,并进而产生负面的社会经济影响(见图1)。开发个人用自动驾驶、联网车辆和用于公共交通的自动驾驶出租车将有助于提高便利性、安全性和经济流动性。图1: 驾驶带来的问题对车辆数字化的需求日益增长,这需要先进的技术、新的架构,还要全面开发创新的组件和解决方案。自动驾驶汽车所需的巨大的高性能算力不仅要用于车辆本身,还要支持基础设施。为了实现数字化移动,汽车原始设备制造商 (OEM) 和一级供应商开始联手片上系统 (SoC) 供应商,共同致力于提供推动汽车行业发展所需的算力。这种范式的转变为制造商带来机会去创造新功能和新特性以满足现代消费者的需求,也有机会让其产品在一众竞争者之中脱颖而出。汽车计算架构的演变图 2 显示了汽车计算架构的演变。过去的汽车,几十个电子控制单元(ECU)遍布车身用于处理本地数据。如今的汽车则由域控制器聚合并处理来自车身各个部分的数据。未来的车辆更将配备中央计算机,提供更高算力来支持高级驾驶辅助功能、高端信息娱乐系统、连接性以及其他先进的功能。图2: 汽车计算架构的演变未来汽车的中央计算机将依靠功能强大的 SoC。这些 SoC 将具有先进的 CPU 和 GPU 功能,能够处理海量的数据并执行复杂的计算,让车辆能够实时做出决策。这样的SoC 需要先进的电源管理解决方案,尤其是核心电压轨的电源解决方案。SoC 核心轨需要几百安培的电流,且有严格的瞬态性能和效率要求。尽管服务器、数据中心和人工智能应用早已使用了多代强大的 SoC 和先进电源管理解决方案,但这些方案对汽车应用来说仍是新事物。汽车电源解决方案还面临更多的挑战,例如需要符合 AEC-Q100 认证和 ASIL-D 功能安全标准,同时还要保持与企业级 SoC 核心电源解决方案相同的高效率、快速瞬态响应、可配置性、可扩展性、监控和系统保护功能。汽车片上系统(SoC)图 3 所示为简化的汽车 SoC 电源树,它包括高功率核心电源轨和低功率系统电源轨两部分。低功率轨可使用电源管理 IC (PMIC) 或离散负载点 (PoL) 变换器。高功率核心轨则需要专门的电源解决方案,因为它们有严格的规范为嵌入到 SoC 中的 CPU 和 GPU 提供所需的功率。此外,根据架构和性能规格,SoC 还可能需要多个核心轨。本文将重点介绍 SoC 核心电源轨的电源解决方案。图3: 汽车SoC的典型电源树SoC 核心轨的传统解决方案使用了模拟脉宽调制 (PWM) 控制器、分立式 MOSFET 以及分立式的电流和温度采样电路(见图 4)。这种解决方案需要很多外部元件,这会增加成本、降低汽车应用的可靠性,并且需要较大的 PCB 空间。因此,传统解决方案不仅设计困难,而且欠缺灵活性和可扩展性。而这两个特性正是高级驾驶辅助系统 (ADAS)、信息娱乐系统和高性能计算 (HPC) 应用中 SoC 的关键需求。图4: 传统SoC解决方案图 5 显示了一个采用了数字多相控制器和单片 DrMOS 功率级的先进 SoC 核心电源解决方案。其中的DrMOS集成了栅极驱动器IC、电流采样电路和温度采样电路。该方案消除了传统解决方案所需的多个外部组件,可以实现更简单的解决方案。图5: 数字PWM控制器和单片DrMOS方案采用单片设计的DrMOS可以提供无可比拟的高功率密度、精确的电流采样和片上温度采样。MPS 拥有22V 和 6V DrMOS 产品系列,可支持单级功率转换和两级功率转换。这些数字控制器具备灵活性和可扩展性,可以根据给定 SoC 核心轨的电流额定值来配置相数。数字控制器不需要任何外部反馈环路补偿,这简化了设计工作并缩短了开发时间。这些器件还具有非易失性存储器 (NVM),可配置和重新配置寄存器设置多达 1,000 次。而且,控制器和 DrMOS 产品还提供各种监控和保护功能,可用于实现系统级遥测。汽车SoC和电池现代汽车多采用两种 12V 电池:铅酸电池或锂离子电池。锂离子电池的最大输出电压(VOUT)高达 20V;铅酸电池的瞬态 VOUT也可以达到40V。图 6 展示了一个采用 22V 额定电压 DrMOS 产品实现的单级功率转换方案。配备12V锂离子电池的汽车可以直接使用22V DrMOS,无需预调节器将电池电压转换为 SoC 核心轨电压。这是实现最佳效率、更小PCB 面积、更低成本和更优电气性能的理想解决方案。对于使用铅酸电池的车辆,在负载突降或双电池条件下的最大电压可达 40V。在这种情况下,需要使用预调节器将 DrMOS 上的输入电压 (VIN) 限制为最大 20V,以在瞬态条件下保护 DrMOS。图 6:使用 22V DrMOS 和可选预稳压器实现的单级功率转换如果车辆配备了铅酸电池,则可以使用预调节器作为限压器。预调节器能够以 100% 占空比运行,这也意味着在正常运行条件下,它提供直通功能,可实现高于99% 的效率。在电压瞬变期间,预调节器则充当降压变换器;在电池电压 (VBATT)超过预设的20V限制时,它能在几毫秒以内将DrMOS的 VIN限制在20V。就电气性能而言,采用预调节器的方案与单级功率转换方案类似,因为预调节器仅在 VBATT瞬间超过 20V 时才被激活。此外,配备预调节器后的 PCB 总面积仍小于传统实现方式,因为后者需要高压分立式 FET 和模拟 PWM 控制器用于单级转换。图 7 显示了一个具有两级功率转换的 12V 铅酸电池供电汽车应用方案。第一级将 VBATT 转换为 5V 或 3.3V 中间总线电压;第二级采用额定电压6V的DrMOS 器件将中间总线电压转换为 SoC 核心电压轨电压。图 7:采用6V DrMOS 实现的两级功率转换两级功率转换需要额外的半导体元件,但与单级解决方案相比,中低功率级 SoC 核心轨的整体 SoC 电源解决方案仍然更小、更便宜。系统设计人员需要权衡所有的因素(例如 12V 电池化学成分和 SoC 核心轨电源规格),以选择最佳的电源架构。图 8 显示的简化应用原理图采用了MPS 的数字多相控制器和单片DrMOS功率级。MPQ2977-AEC1配置为两个输出轨,每个轨三相。这个全面的解决方案只需很少的外部组件,同时还提供多种监控和保护功能,例如过流保护 (OCP)、过压保护 (OVP) 和过温保护 (OTP)。图8: MPQ2977除此之外,数字控制器也是 MPS 汽车MPSafeTM系列产品的一部分。该系列产品均为根据 ISO 26262 功能安全产品开发流程开发的面向安全的汽车级产品。随着汽车行业对自动驾驶、互联化和电气化的不断追求,ISO 26262 国际标准已成为应对电气和电子系统故障风险的核心要求。MPSafeTM产品开发流程确保了汽车产品被恰当地开发,帮助客户满足高达ASIL-D的各种汽车安全完整性等级 (ASIL) 要求。结语汽车行业正经历一系列的数字化转型,它不断迈向自动驾驶、高端信息娱乐系统、连接性和共享出行,以解决当今驾驶员和乘客共同面临的问题。汽车计算架构也随之从分布式架构演变为具有强大 SoC的集中式架构。中央计算中采用的 SoC 需要先进的电源管理解决方案加持,尤其是核心电压轨。传统的电源解决方案已不再适用于下一代的中央计算电源应用。汽车 SoC 核心电源应用中使用的先进电源管理解决方案、数字多相控制器和 DrMOS 功率级必须是具备可扩展性、灵活性且紧凑的电源解决方案,同时还要具备高效率和快速瞬态响应。本文介绍了如何实现单级或两级功率转换的电源架构。要了解MPS 汽车 SoC 核心电源解决方案的更多信息,请查阅我们的 AEC-Q100 级多相数字控制器和DrMOS 功率级产品。
 哦! 它是空的。
哦! 它是空的。