


 4008-622-911
4008-622-911




下顿馆子,完美诠释了电子工程师为什么不愿意改设计?
看看,做项目的就是这么样吧!
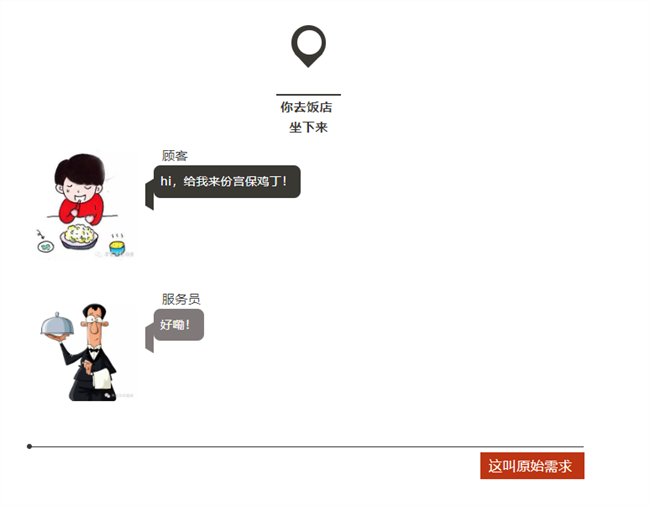
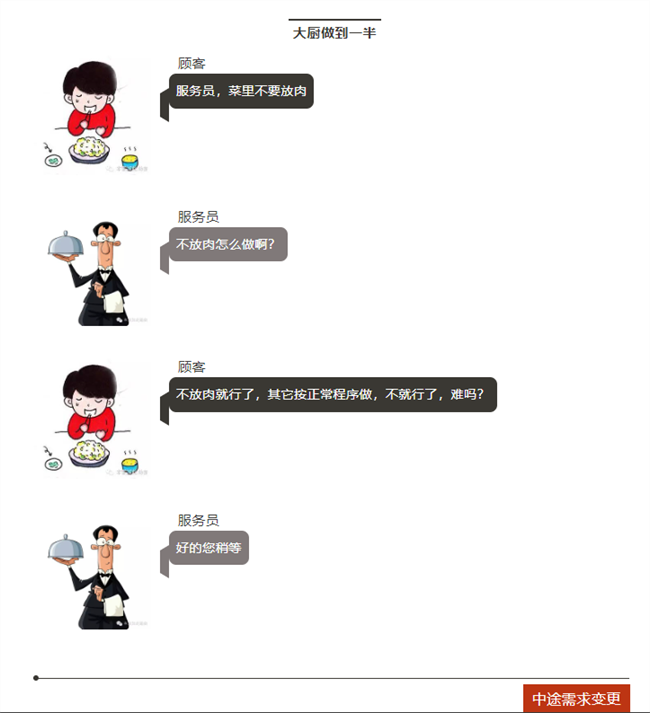
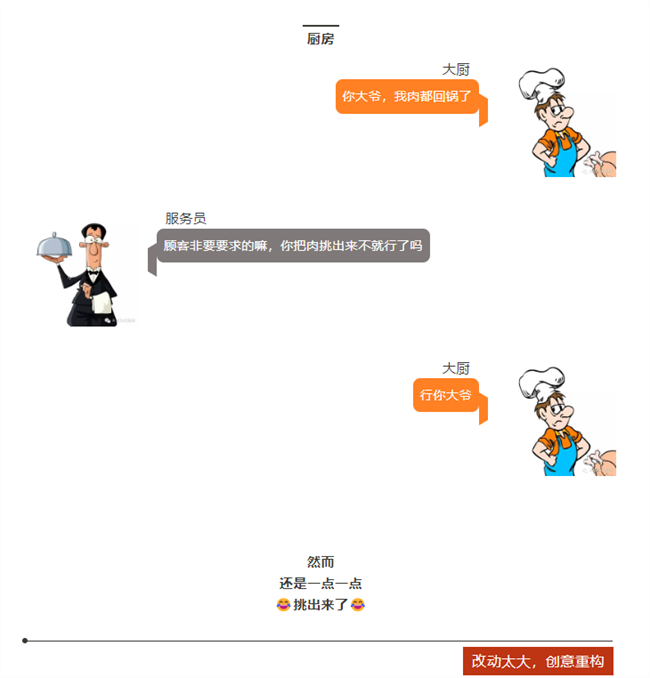

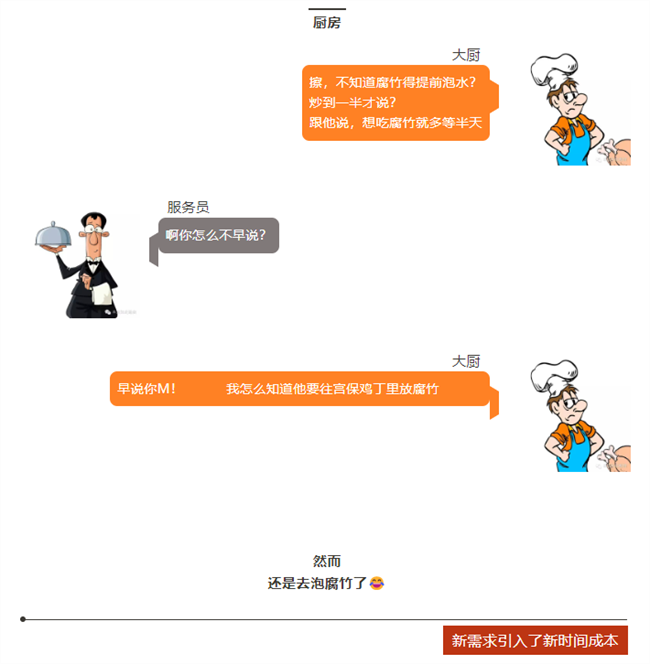
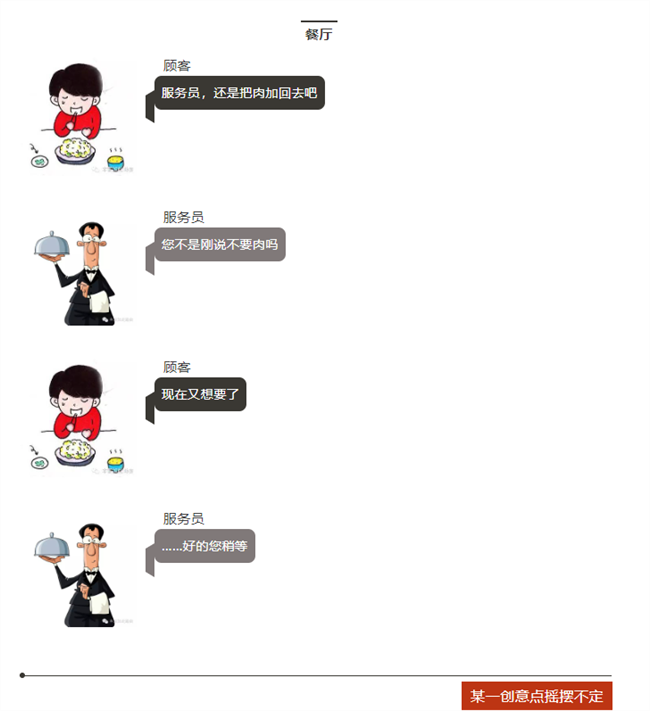
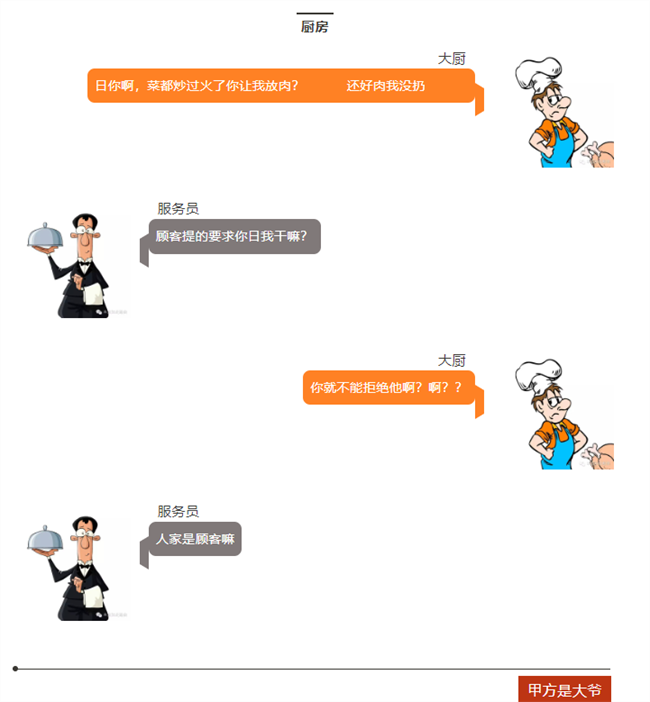
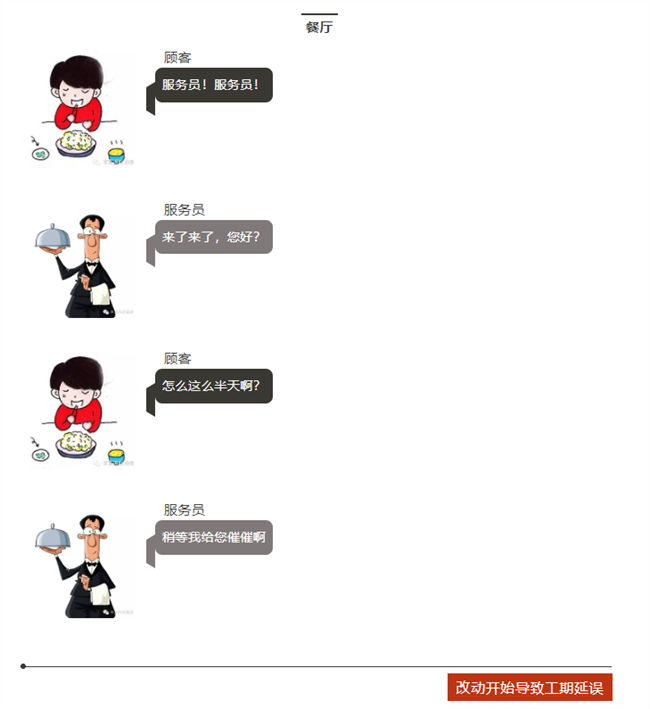


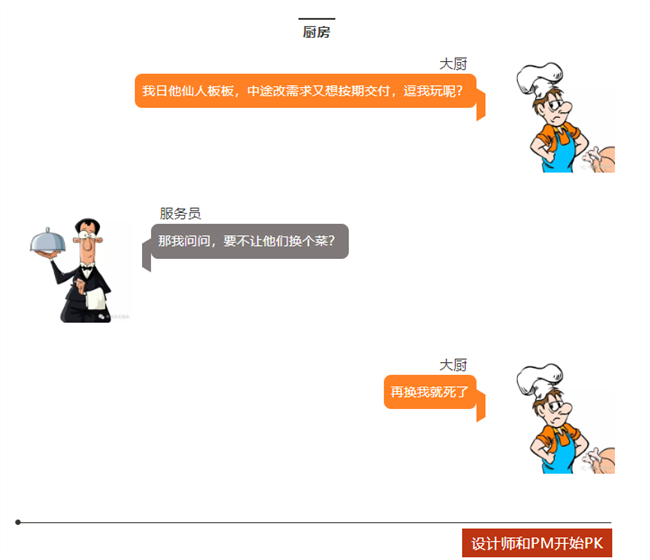
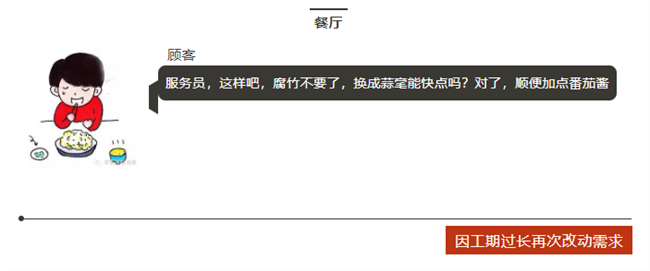
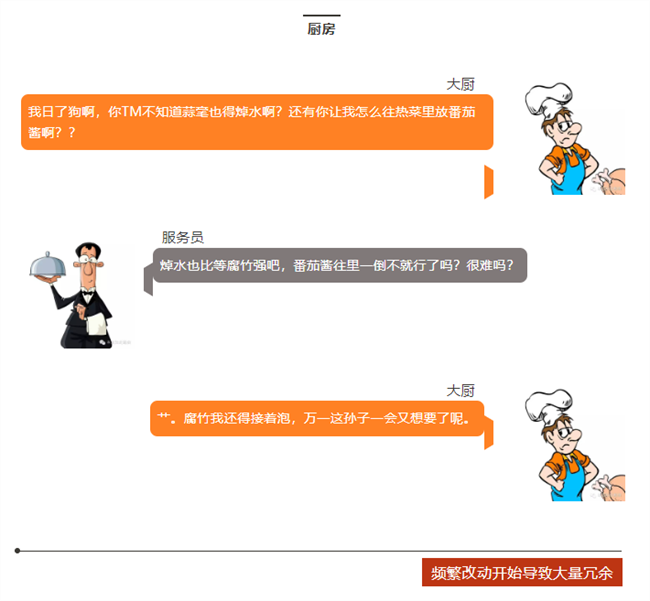

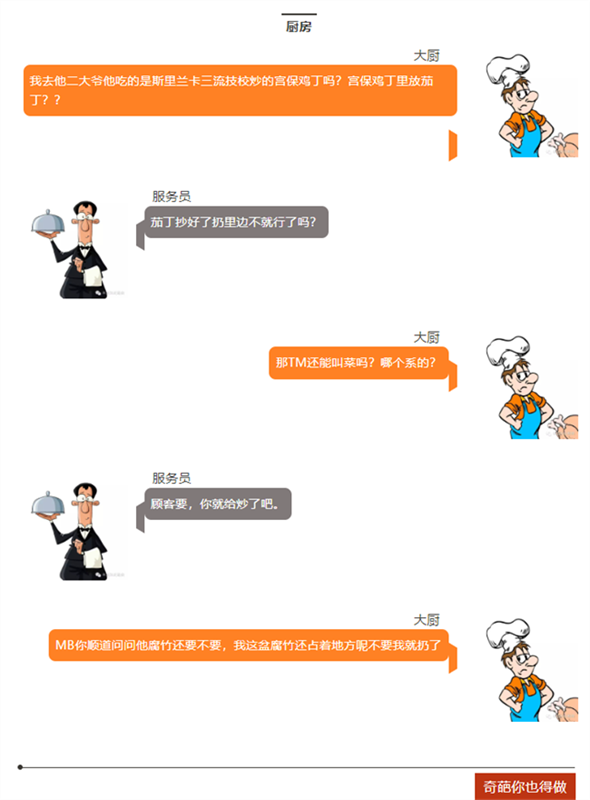


顾客=客户,服务员=老板,大厨=工程师。
有同感的工程师。。


相关推荐
-

-
中国芯片企业押注RISC-V架构,RISC-V架构受美国限制的可能性分析
中国芯片企业押注RISC-V架构,RISC-V架构受美国限制的可能性分析作为国家的重点发展方向之一,芯片产业一直备受关注。而RISC-V架构成为了中国芯片企业押注的对象。那么,这样的押注是值得的吗?RISC-V架构会受到美国的断供限制吗?本文将对此进行阐述。RISC-V架构的兴起在CPU领域,x86、ARM、RISC-V三分天下已成为事实。其中,RISC-V架构的兴起具有非常重要的意义,它是一种免费、开源的指令集架构,能够自由地进行设计、制造和销售RISC-V芯片和软件。因此,RISC-V架构的兴起吸引了世界各地的众多公司和开发者,推动了RISC-V生态的快速发展。同时,在中国,RISC-V架构也得到了广泛的关注和支持。中国工程院院士倪光南曾预言,未来在CPU领域,RISC-V架构有望跻身三分天下之列。中国芯片企业的押注面对RISC-V架构的兴起,中国芯片厂商纷纷押注,特别是阿里、华为、紫光展锐、中兴通讯、中科院等巨头级企业都在研发RISC-V芯片。这些厂商研发RISC-V芯片,不仅是因为它是开源免费的,而是因为RISC-V架构具有更好的性能和更低的功耗,能够更好地满足市场需求。同时,RISC-V架构的可扩展性也使得它能够更好地适应不同的场景。其中,阿里已经推出了各种各样的RISC-V芯片,覆盖了PC、手机、服务器、AI、物联网等领域。同时,谷歌也宣布将支持安卓系统对RISC-V芯片的支持,Linux系统也已经支持RISC-V芯片,这意味着RISC-V芯片将有很广阔的市场前景。RISC-V架构受美国限制的可能性分析然而,也有人表示担心RISC-V架构会受到美国的限制。因为RISC-V架构起源于美国加州大学伯克利分校,因此,RISC-V架构本身就是美国的。但实际上,RISC-V架构已经得到众多国家和企业的支持和参与,经过多年的完善和补充,已经成为众多开发者的共同成果,而不再属于美国和任何一个特定的公司或组织。同时,RISC-V基金会已经从美国加利福尼亚州转移到瑞士工作,它不属于任何公司,有70多个国家和3000多家企业入驻,80%以上的最高会员是中国企业。换言之,RISC-V架构已经真正实现了开放和共享,没有任何一个单一的国家和组织能够将其私有化,美国也不可能断供。综合来看,RISC-V架构作为免费、开源的指令集架构,已经得到众多国家和企业的支持和参与。虽然它的起源是美国,但已经像Linux内核一样,全球任何人和机构,都可以基于任何目的来使用它,不会受到限制。因此,当下中国芯片企业押注RISC-V架构,是非常明智的选择,将促进RISC-V生态的繁荣发展,进一步推进中国芯片业的发展。
-

-
TDK推出两款铜内电极压电执行器
TDK株式会社推出两款新的采用符合RoHS要求的锆钛酸铅 (PZT) 材料制成的铜内电极压电执行器——COM30S5和COM45S5。新款元件采用TDK获得专利的基于铜电极的HAS(高有效堆叠)技术,以无外壳封装的被动元件供货,实现了良好的动态范围、高力量/体积比和纳米级精度。比之其他技术,TDK采用HAS技术的压电执行器性能更佳,湿度稳定性更好、使用寿命更长。两款新元件覆盖电压范围为-10至+180 V,额定位移在+160 V处达到,允许的表面温度范围为-40至+160°C,高度分别为30 mm和45 mm,横截面尺寸为5.2 mm x 5.2 mm,并且在160 V和730 N的预紧力条件下可实现55 µm (COM30S5) 和83 µm (COM45S5) 的位移。此外,TDK计划于2023年再推出另外三款执行器,以满足更广泛的应用要求。目前,这些执行器仅作为少量原型样品供应,尚未量产,具体包括高度为10 mm、位移量为16 µm的COM10S5;高度为27 mm、位移量为47 µm的COM27S3(带引线型);以及高度为30 mm、横截面为7 mm x 7 mm、位移量为55 µm、推力高达2600 N的COM30S7。TDK的压电执行器口碑好,应用范围广,适合包括纳米级定位技术、工艺工程中液体和气体的高精度阀门控制,以及半导体制造等高端解决方案在内的诸多应用。主要应用● 纳米级定位系统● 液体和气体的高精度阀门控制● 焊线机主要特点和优势● 铜内电极,具有优异湿度稳定性和高性价比● 更小的无效区域,更好的性能,更长的使用寿命和更紧凑的设计● 采用无铅高熔点金属焊接,适合高温操作关键数据
 哦! 它是空的。
哦! 它是空的。